SCC 알고리즘 목적
해당 알고리즘의 목적은 사이클을 한 개의 노드로 묶는 것을 목적으로 하며 이 알고리즘은 위상 정렬에서 많이 사용됩니다. 위상 정렬은 사이클이 없는 그래프, 즉 dag라는 조건이 있어야 했는데요. 하지만 실제 복잡한 그래프는 사이클이 존재하는 그래프가 매~우 많습니다. 이런 상황을 다루기 위한 테크닉이 바로 SCC 알고리즘이 되겠습니다!

강한 연결 요소 Strong Connected Component의 Group에 속하는 노드는 u, v 에 대하여 u->v로 항상 이동이 가능한 집단을 말합니다. SCC알고리즘은 이런 조건을 만족하는 노드를 grouping하는 것입니다!
일반적인 그래프(트리 포함) -> Dag(트리 포함x) 변환!
작동 메커니즘
문제 출처 : https://www.acmicpc.net/problem/2162
전체적인 메커니즘은 임의 한 노드에서 dfs탐색을 시작하며 dfs트리를 만듭니다. 그 과정에서 노드에 숫자를 부여할거고 부여할 숫자는 계속 1씩 증가합니다. 그러면 부모가 항상 자식보다 작은 숫자를 갖게 될겁니다.
저희의 목적은 가장 큰 사이클을 1개의 그룹으로 분류하는 것인데, 정확히 말하면 어느 집단에 속하는 노드 u,v에 대하여 u->v로 항상 갈 수 있는 가장 큰 집단으로 나누는 것입니다. 표현하기에 따라 다르지만 u->u 로도 항상 갈 수 있다고 말할 수 있습니다. 따라서 1개의 노드도 사이클을 만든다고 생각할 수 있으며 하나의 그룹으로 분리될 수 있습니다.
아래와 같은 상황에서는 {a,b,e}, {f, g}, {c,d}, {g} 로 분리될 수 있습니다. 어떻게 분리했는지 간단히 알아보죠!
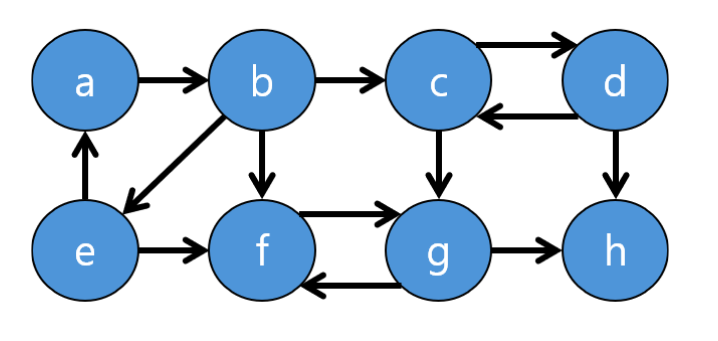
일단 알파벳 순서로 간다고 생각해보면...
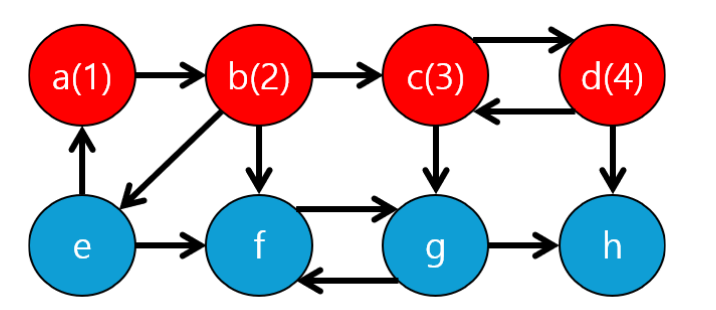
이런 형태가 될텐데요... 빨간색은 방문했다는 것을 의미하면 숫자는 노드에 부여한 숫자입니다. 겉보기엔 {c,d} 로 바로 묶이는게 맞을 것 같지만 계산적으로 판단되지 않았습니다. 쫌더 지켜보면..
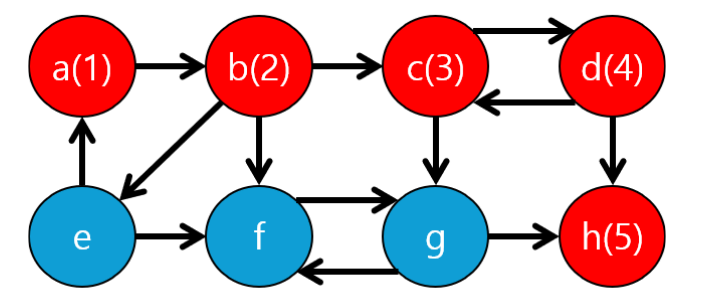
h를 5번째로 탐색하는데 h에서 더이상 갈 수 있는 곳이 없습니다. 또한 h의 자식 중에서(해당 상황에선 empty array 일반화하여 말하겠습니다) 조상으로 갈 수 있는 방법이 없습니다.
이를 판별하는 방법은 h(5)의 5라는 숫자가 h의 자식들(empty)이 갈 수 있는 노드의 번호의 최솟값이 5보다 크기 때문입니다. 따라서 5는 자기 자신이 한 개의 그룹으로 분류될 수 있습니다.
해당 과정에서 설명하지 않은 개념이 있는데 다른 과정에서 살펴보겠습니다.
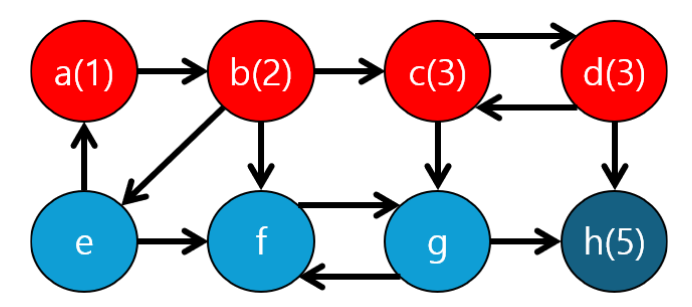
h는 SCC분리 작업이 끝났으니 별도로 chk해주고... 다음 d와 같은 경우엔 c로 갈 수 있는 간선이 더 남아있으므로 c로 갈라고 하는데... 이미 이전에 가본 장소네요.. 일단 이미 가본 장소를 또 가본다는 것 자체가 사이클을 만든다는 거지만 최대 크기의 사이클을 만들기 위해 아직 분리하진 않겠습니다.
그럼 일단 d와 d의 자식들이 갈 수 있는 가~장 위의 조상 노드, 즉 가질 수 있는 번호의 최솟값은 min(h(5), d(4), c(3)) = 3 이 되므로 d의 번호를 3으로 업데이트 해줍니다. 이 때 c는 이미 가본 장소이므로 dfs에 들어가진 않습니다. 일단 d노드에 대해 탐색은 끝났으므로 3이라는 최솟값을 return하며 c로 돌아갑니다. 그리고 c에는 아직 더 갈 수 있는 노드가 있으니 이를 방문해줍니다.
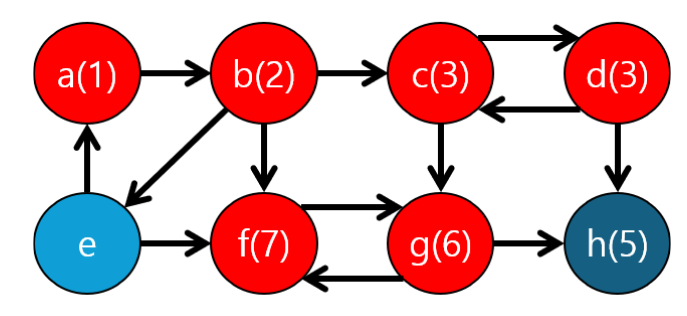
이때 f에서 더 갈 수 있는 곳은 g이기 때문에 아래와 같이 업데이트하면 아래와 같이 나타납니다.
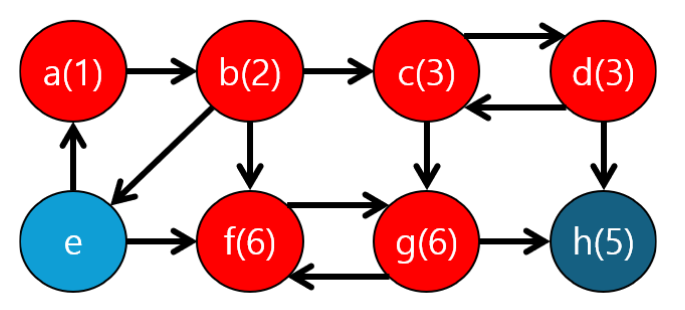
근데 g의 자식들이 갈 수 있는 가장 위에 존재하는 조상노드는 6번인데... g자신이네요! 그렇다면 g의 자식들을 그룹핑하면 됩니다! 근데 어떻게 하면 좋을까요? 여기서 생각해봐야 할 것은 dfs과정이라는 사실이며 이미 분리된 노드는 어떤 자료 구조에서 제외된 상태라는 것입니다. 존재하는 정보 중, 가장 최근에 방문한 노드를 꺼낼 수 있는 자료구조는 "스택(Stack)" 입니다.
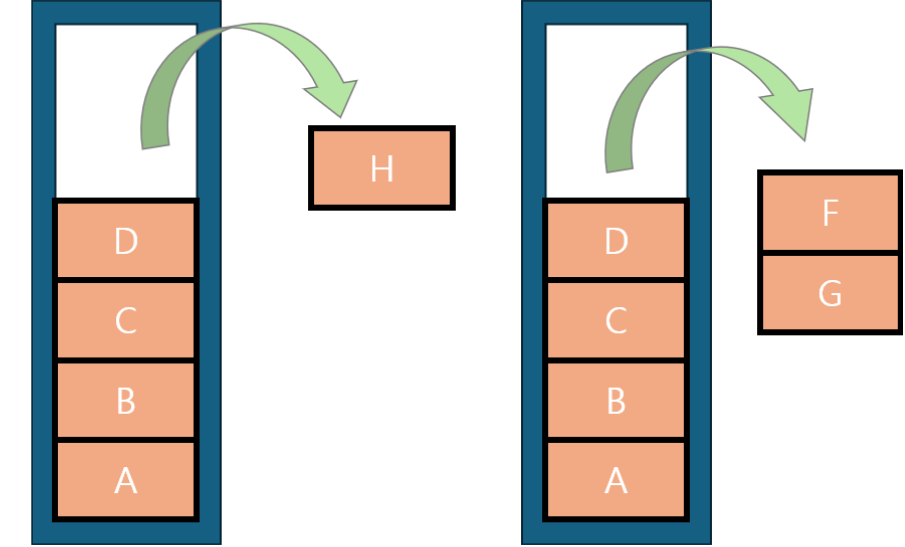
사실은 이전부터 방문한 노드들은 stack에 들어가고 있었고 자기 자신이 최상위 조상 노드(+자식들이 갈 수 있는..)가 자기 자신일 경우 자신이 될때까지 stack에서 pop하는 과정을 거치며 자식 노드들을 vector group에 저장하고 vector<vector> groups 에 담아서 저장하고 있었습니다. 여기서 바라볼 것은 이전에 노드에 숫자를 부여한 것인데, 이 숫자의 대소관계를 통해 조상을 확인할 수 있다는 사실입니다. 간단하고 재밌는 테크닉이였습니다.
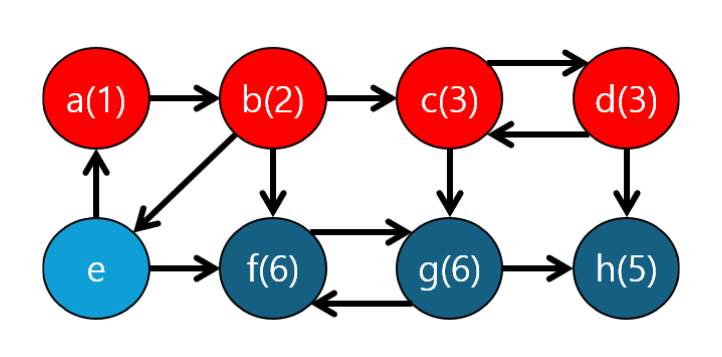
f,g에 대해서도 끝났으므로 따로 check해주고 min(3,6) = 3 은 c 자신이므로 위와 같은 과정을 반복하고...

b와 인접한 노드 중 f는 이미 갔던 노드이기도 하며 분리된 노드이기도 합니다. 이전에 이미 간 노드들은 다시 방문하지 않고 해당 노드가 갈 수 있는 조상의 노드를 업데이트 해줬는데요 (노드 숫자의 최솟값 갱신을 통해서) 이 경우엔 이미 분리됬으므로 이런 과정도 없이 그냥 무시합니다. (분리여부 check배열 / 갈 수 있는 최상위 조상노드 저장배열 2개!!)
그리고 e로 이동하면... e에서도 마찬가지로 f에 갈 수 있지만 위와 같은 이유로 아예 무시하고 a를 보는데... a는 이미 갔긴 했어도 분리되지 않았습니다. 따라서 e가 갈 수 있는 조상(나 포함) 노드는 min(1,8) = 1번 노드 입니다. 이제 e는 갈 수 있는 곳이 없으므로 해당 정보를 b에 넘겨주고, b도 갈 곳이 없으므로 a에 정보를 넘겨줍니다.

a와 a의 자식들이 갈 수 있는 노드 중, 가장 상위의 조상( = 가장 작은 노드 번호)은 1인데 a자신 이므로 stack에서 a가 될때까지 pop해주면서 grouping해주면 최종적으로 아래와 같은 결과를 볼 수 있습니다.

그리고 다른 알고리즘에 적용하기 위해 새로운 dag 그래프를 만들어야 하는데요. 이는 같은 색깔의 노드들을 그냥 1개의 노드로 생각하고 만들어주면 됩니다. {h} : 1, {f,g} : 2, {d,c} : 3, {e,b,a} : 4 라고 그룹 넘버링이 진행하면 (생성 순서) 기존의 모든 간선에 대하여 u->v로 가는 간선을 num[n] -> num[v] 로 간다고 처리하면 됩니다. 그리고 이번엔 사이클이 존재하면 안되므로 같은 그룹일 경우 무시하면 됩니다.
참고로 stack pop 하면서 num을 부모 노드말고 group의 번호로 저장해 주는 것이 더 효율적인 코드입니다. 즉 위에서는 그냥 노드의 부모 노드로 업데이트 했지만 그냥 group_cnt 로 업데이트하는 것이 더 좋다는 거죠... (설명할 땐 그냥 진행했습니다)
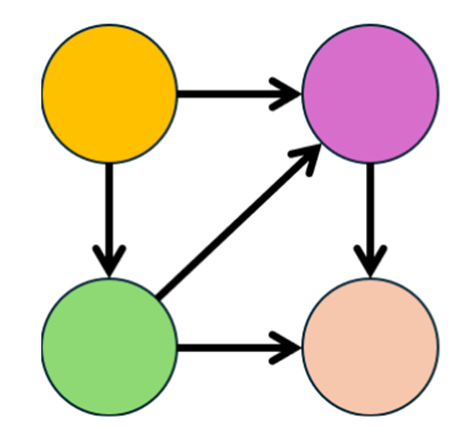
결과적으로 이런 dag그래프를 만들 수 있습니다.
2150번 코드
#include <bits/stdc++.h>
using namespace std;
#define SIZE 10005
int N, M,num[SIZE],chk[SIZE],cnt;
vector<int> v[SIZE];
vector< vector<int> > group;
stack<int> st;
int dfs(int loc)
{
num[loc] = ++cnt;
int res = num[loc];
st.push(loc);
for(auto&i:v[loc]){
if(!num[i]) res = min(res, dfs(i));
else if(!chk[i]) res = min(res, num[i]);
}
if(res == num[loc]){
vector<int> path;
while(1){
int t = st.top(); st.pop();
chk[t] = 1;
path.push_back(t);
if(loc == t) break;
}
sort(path.begin(), path.end());
group.push_back(path);
}
return res;
}
int main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
int x, y;
cin>>N>>M;
for(int i=0;i<M;i++){
cin>>x>>y;
v[x].push_back(y);
}
for(int i=1;i<=N;i++)
if(!num[i]) dfs(i);
sort(group.begin(), group.end());
cout<<group.size()<<"\n";
for(auto&g:group){
for(auto&i:g)
cout<<i<<" ";
cout<<"-1\n";
}
}
SCC는 처음 접할 때는 복잡하게 느껴졌습니다. 왜냐하면 간선을 3가지로 정의했기 때문인데요, 저는 이해하기 쉽도록 일반화(?) 화여 설명해봤습니다. 이번 포스팅에선 제가 처음에 이 알고리즘을 이해할 때 힘들었던 부분을 최대한 풀어서 설명하기 위해 길게 써봤는데요, 포스팅하면서 더 정확히 이해할 수 있었던 것 같습니다. 알고리즘을 무작정 외우기 보단 이해하고 쓰도록 합시다!
'코딩 > 알고리즘' 카테고리의 다른 글
| [알고리즘 문제] 25402번 트리와 쿼리 (0) | 2024.05.29 |
|---|---|
| [알고리즘] ccw와 선분교차 판정 (0) | 2024.05.12 |
| [알고리즘 문제] 2316번 도시 왕복하기 2 (1) | 2024.05.01 |
| [알고리즘 개념] Network Flow 최대 유량 알고리즘 (feat. 6086번 풀이) (0) | 2024.04.29 |
| [알고리즘 문제] 13250번 주사위 게임 (feat. 탑-다운, 바텀-업) (0) | 2024.04.12 |